RGB-D-Fusion - Image Conditioned Depth Diffusion of Humanoid Subjects
We present RGB-D-Fusion, a multi-modal conditional denoising diffusion probabilistic model to generate high resolution depth maps from low-resolution monocular RGB images of humanoid subjects. RGB-D-Fusion first generates a low-resolution depth map using an image conditioned denoising diffusion probabilistic model and then upsamples the depth map using a second denoising diffusion probabilistic model conditioned on a low-resolution RGB-D image. We further introduce a novel augmentation technique, depth noise augmentation, to increase the robustness of our super-resolution model.
Authors: Sascha Kirch, Valeria Olyunina, Jan Ondřej, Rafael Pagés, Sergio Martín & Clara Pérez-Molina
![]()
Overview
Our RGB-D-Fusion framework takes an RGB image as input and outputs an RGB-D image using perspective projection. We first downsample the input image from 256×256 to 64×64. We then predict the perspective depth map using a conditional denoising diffusion probabilistic model. We then combine the predicted depth map with the input RGB into an RGB-D image of resolution 64×64. We further apply a super-resolution model conditioned on the low-resolution RGB-D to obtain a high-resolution depth map. The predicted high-resolution depth map is combined with the input RGB to construct the final output: a high-resolution RGB-D image. To reconstruct the real depth in camera coordinates, a projection matrix can be applied if available.
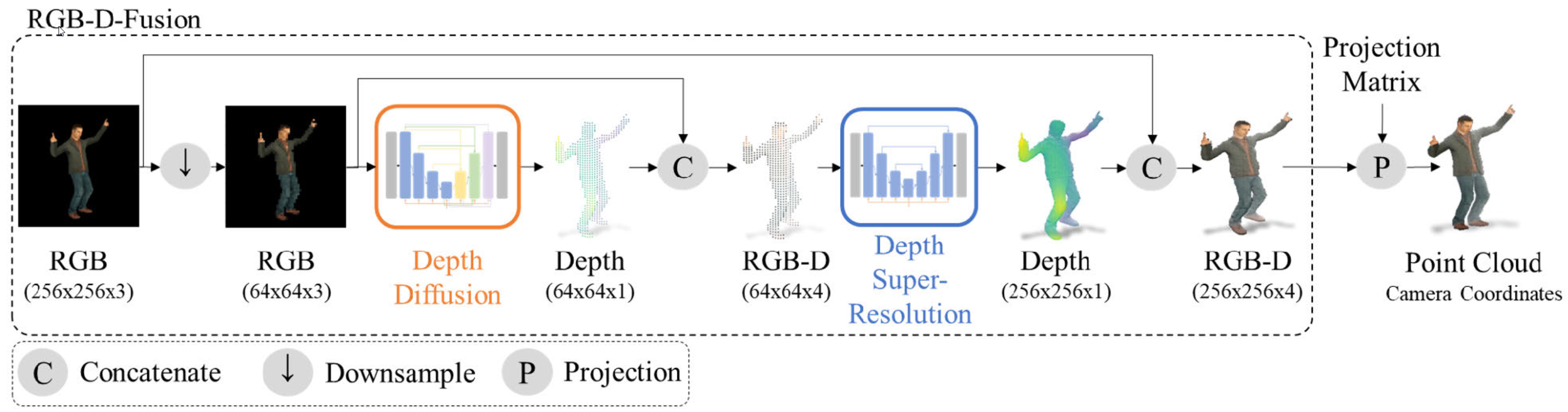
Contribution
- We provide a framework for high resolution dense monocular depth estimation using diffusion models.
- We perform super-resolution for dense depth data conditioned on a multi-modal RGB-D input condition using diffusion models.
- We introduce a novel augmentation technique, namely depth noise, to enhance the robustness of the depth super-resolution model.
- We perform rigorous ablations and experiments to validate our design choices
Results
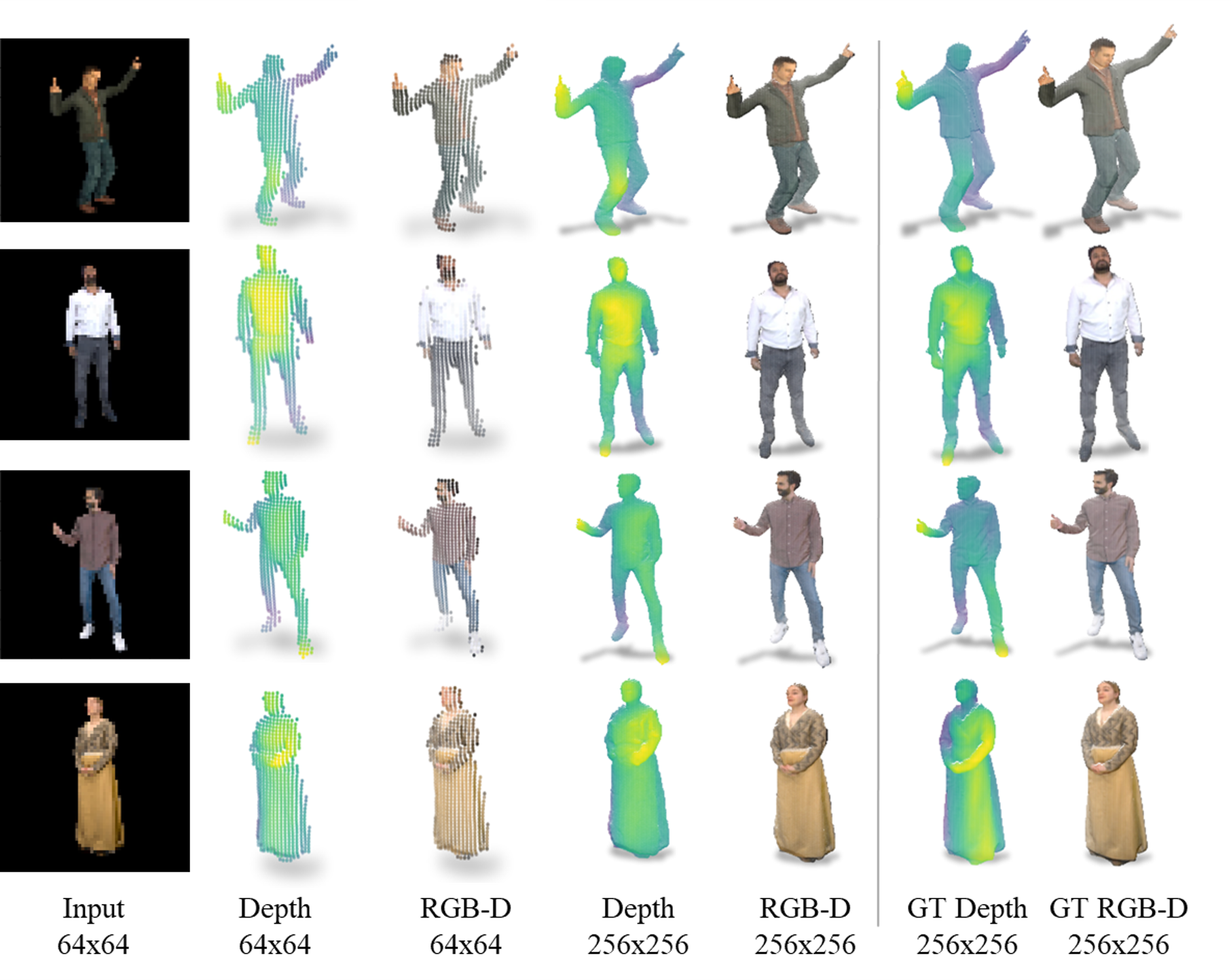
Prediction vs. GT
Inference results on the test set of our RGB-D-Fusion framework at various stages compared to the ground truth. The 64x64 depth is generated by our depth diffusion stage. The 256x256 depth is generated from the 64x64 depth using our depth super resolution diffusion model.
In the wild predictions
Outputs of our RGB-D-Fusion framework for the given input images where no ground truth is available. Original images are taken with a variety of single-view mobile cameras.



Citation
If you find our work helpful for your research, please consider citing the following BibTeX entry.
@article{kirch_rgb-d-fusion_2023,
title = {RGB-D-Fusion: Image Conditioned Depth Diffusion of Humanoid Subjects},
author = {Kirch, Sascha and Olyunina, Valeria and Ondřej, Jan and Pagés, Rafael and Martín, Sergio and Pérez-Molina, Clara},
journal = {IEEE Access},
year = {2023},
volume = {11},
issn = {2169-3536},
doi = {10.1109/ACCESS.2023.3312017},
pages = {99111--99129},
url = {https://ieeexplore.ieee.org/document/10239167},
}