Adversarial Domain Adaptation of Synthetic 3D Data to Train a Volumetric Video Generator Model
In cooperation with Volograms we synthetically generated training data from an existing (similar but different) data distribution by performing adversarial domain adaptation using an improved CycleGAN to train a single-view reconstruction model for VR/AR applications.
Authors: Sascha Kirch, Sergio Arnaldo, Rafael Pagés, Sergio Martín & Clara Pérez-Molina
Contributions
- A CycleGAN based framework, the VoloGAN, that performs the joint domain adaptation of images and their respective depth.
- The proposal of a channel wise loss function, where each channel can be weighted independently to mitigate the impact of channel pollution caused by the early fusion approach of the image and depth channels.
- The implementation of a gated self-attention block where the gate is controlled by a learnable scalar.
- The evaluation of our method using a dataset containing monocular images and depth maps of humans recorded with a consumer depth sensor and camera.
Overview
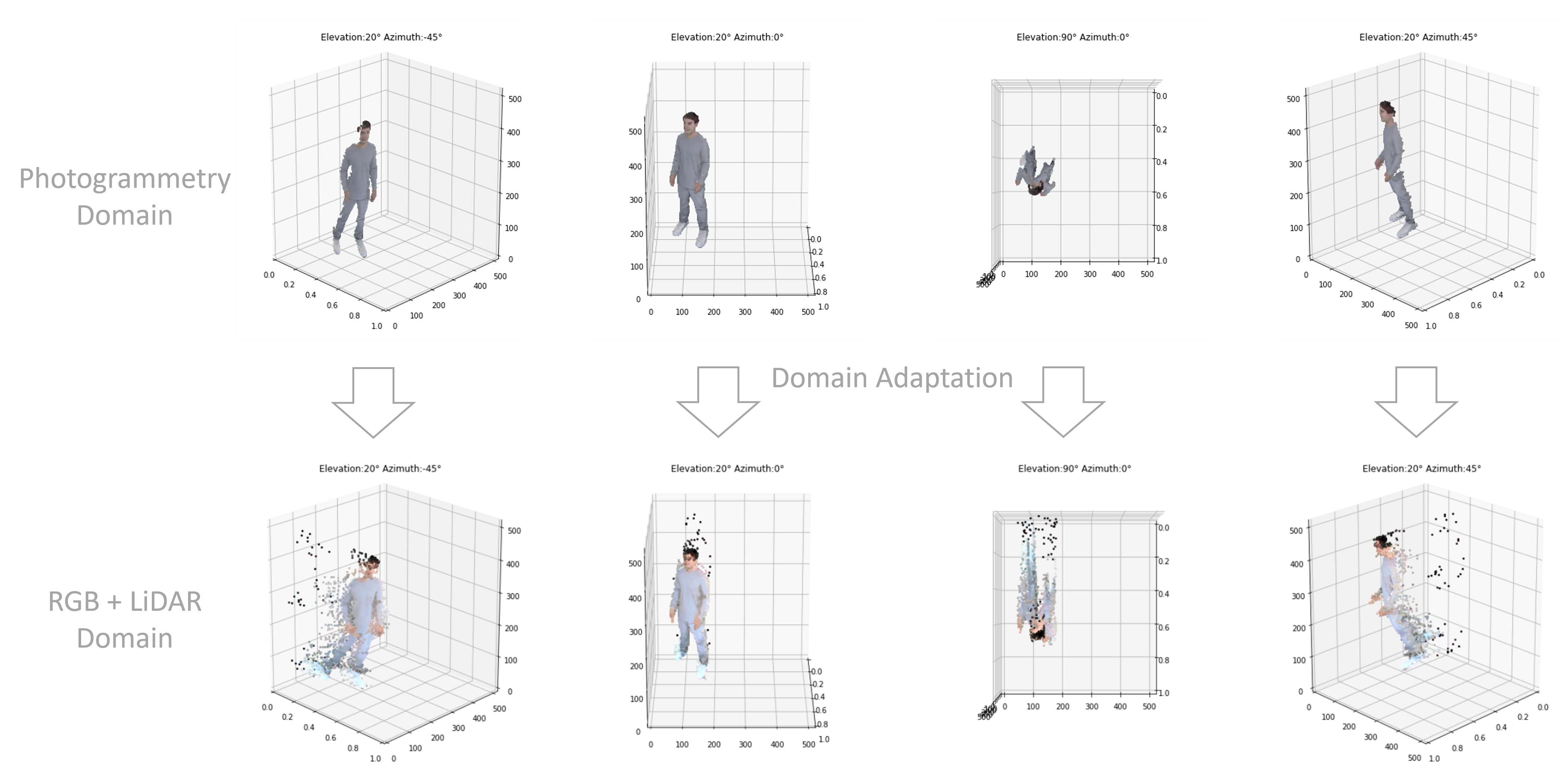
Both data domains consist of RGBD images with the dimensions 512x512x4. Images from the first domain are generated using photogrammetry and images from the second domain are generated from a mobile phone using a LiDAR scanner. The objective of this work has been to translate RGBD images generated using photogrammetry to images that appear to be from the domain generated by the LiDAR scan.
Training a machine learning model requires representative training data of the target application. In some cases, data is either not available in the required amount or only similar data from another data domain is available. Data can be synthetically generated by translating data from one domain into another domain. Adversarial domain adaption is the process of translating data from a source domain into a target domain using adversarial learning approaches. Since none of the samples is available in both domains, adversarial domain adaptation is an unsupervised learning problem. The CycleGAN framework is a generative adversarial network that is used for unpaired data-to-data translation tasks. It is built from one generator and one discriminator for each domain that are trained simultaneously. The challenge of training CycleGANs lies primarily in the high amount of hyperparameters and the difference in complexity between the discriminator and the generator. Furthermore, the learning objective is qualitatively more complex for the generator than for the discriminator. In addition, especially for convolutional networks that translate high resolution multi-channel images, models become complex and require many resources to train.
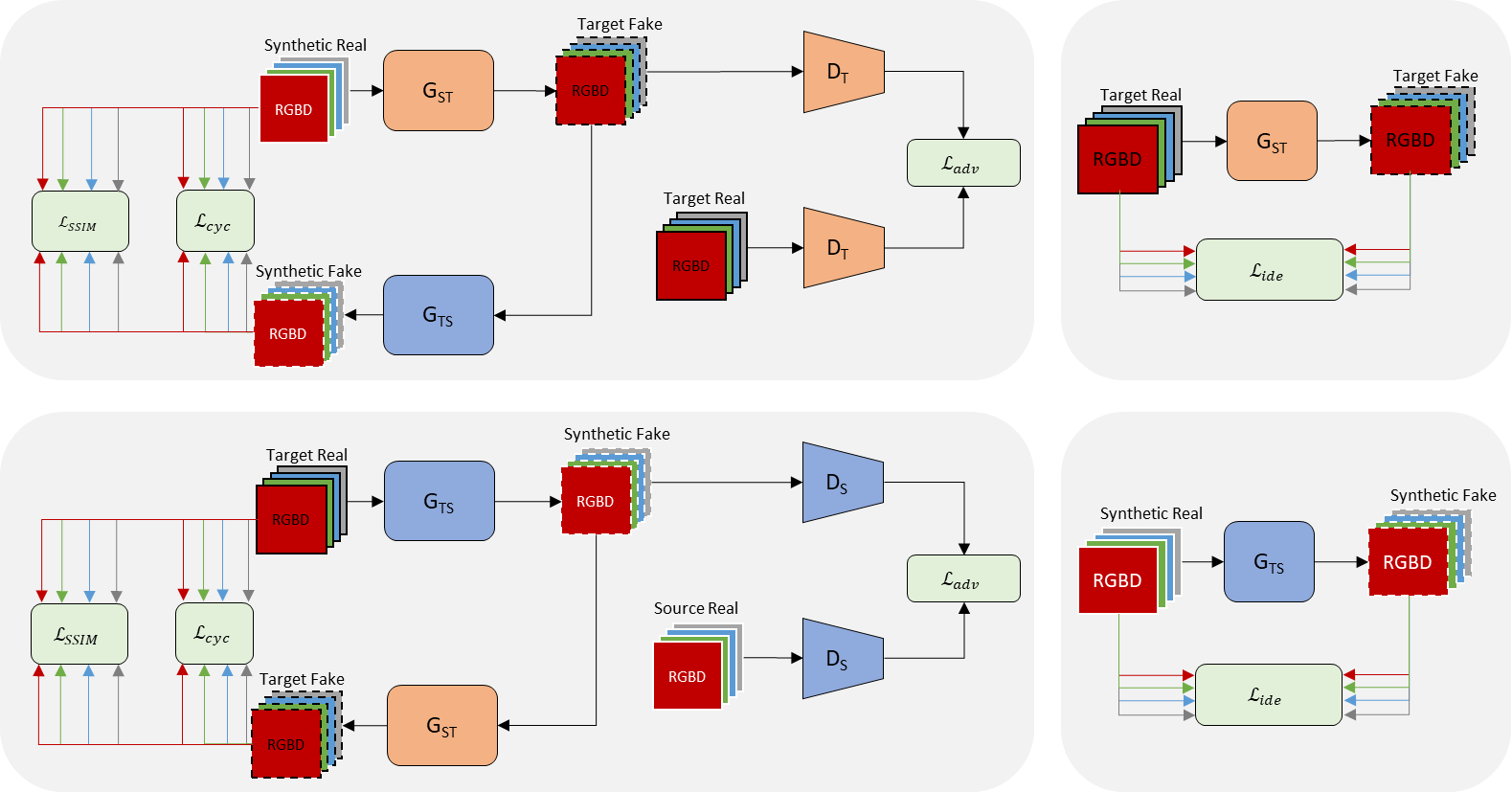
The VoloGAN Framework
Our VoloGAN framework consists of four models: two generators and two discriminators. The generators translate an RGB-D image from one domain into the respective other domain. The discriminators predict whether a generated RGB-D is real or fake. We incorporate four loss terms: adversarial loss, a channel-wise cycle-consistency loss, a channel-wise structural similarity loss of cycled image pairs and an identity loss.
Results
Following generated RGB images and depth maps using the target generator model. This generator takes an RGB-D image from the Photogrammetry domain and translates it in to the RGB+LiDAR domain.

